using Flux
f(x) = sum(tanh.(W * x))
W = rand(2,2)
x = rand(2,1)
# a single instance
dfdw = gradient(()->f(x), Flux.params(W))
# as a do block
g = gradient(Flux.params(W)) do
f(x)
endGrads(...)A Julia approach to Machine Learning
Time consuming.
Full of boilerplate.
Often inefficient.
These imply packages are useful!
Flux is a Julia package.
It is hackable, extensible, and provides nice syntatic sugar.
Relies on Zygote which is an automatic differentitation package.
Revisit primary concepts: automatic differentation, optimisation, loss functions.
Grammar of Flux.
Basic Flux Usage.
Constructing Neural Networks.
Loss functions allow objective of the network to be found.
Constructed to measure difference between regressors and data.
Common loss functions are mse, logitcrossentropy, binarycrossentropy, etc.
A loss function may be optimised in any way.
The random sampling method is as efficient as any for finding global minima.
Finding local minima (or just reducing loss) is most often done through gradient descent.
Backbone of machine learning.
Newtons method or gradient descent is an optimisation method.
Can be computed symbolically, numerically, or automatically: \[ \frac{df}{dx} = \lim_{h\rightarrow 0} \frac{f(x+h) - f(x)}{h} \]
Define a dual number as: \(d(x) = (x, \epsilon)\)
By Taylor series the derivative is given by \(\epsilon\).
Julia: operator overload all the usual functions to handle dual numbers.
Differentitation is now arbitrary precision and cheaper to compute.
Backpropagation is the machine learning algorithm.
Errors are back-propagated through layers of network.
Under the hood: chain rule. \[\frac{\partial F}{\partial x} = \frac{\partial f_1}{\partial f_2}\frac{\partial f_2}{\partial f_3}\ldots\frac{\partial f_n}{\partial x}\]
There are many automatic differentation packages in Julia: Flux uses Zygote.
The API call is gradient and is used in two ways: functions and do blocks.
Each method needs to specify the parameters which will be differentiated through Flux.params conversion.
using Flux
f(x) = sum(tanh.(W * x))
W = rand(2,2)
x = rand(2,1)
# a single instance
dfdw = gradient(()->f(x), Flux.params(W))
# as a do block
g = gradient(Flux.params(W)) do
f(x)
endGrads(...)Gradient descent is defined as: \[W_{t+1} = W_t - \eta \frac{\partial L}{\partial W} \]
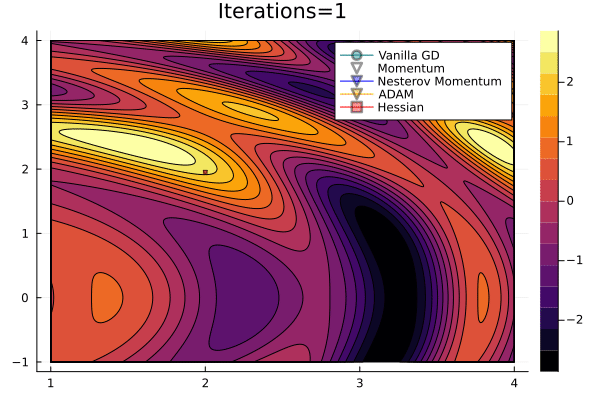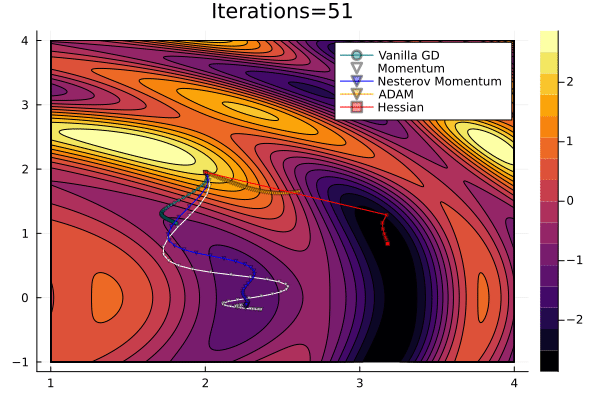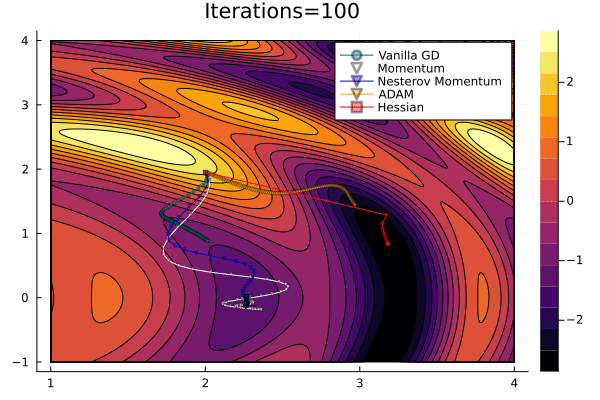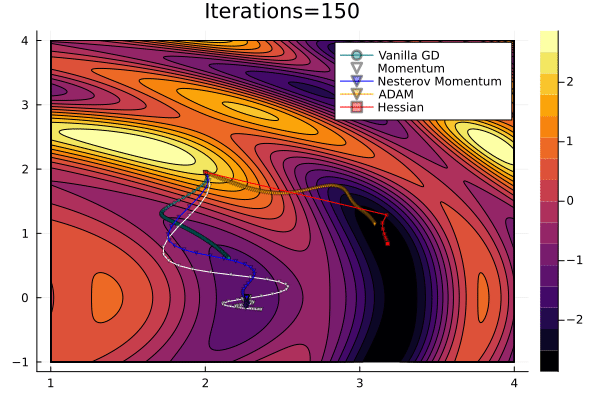
Gradient descent may be accelerated by momentum.
Flux has support for multiple optimisers through an optimiser object class: opt(lr, hyperparams)
Descent(lr), Momentum(lr, alp), ADAM()
Gradient Descent Comparison
Gradients can be approximated by a subset of data.
Stochastic Gradient Descent is when these subsets are chosen randomly.
Helps avoid local minima and alleviates computer memory constraints.
The activation function mimics the firing rate of a neuron.
It provides a non-linearity to allow for complex learning manifolds.
Flux supports all the common functions: tanh, relu, σ, etc.
Neural networks are composed as layers of weights.
Flux offers default layers which can be found in the documentation: Dense, Conv, MaxPool, RNNCell etc.
We can also define our own custom layers by a structure.
Zygote differentates through structure fields
struct CustomDense
W
b
function CustomDense(dimsin::Int, dimsout::Int)
W = rand(dimsout, dimsin)
b = rand(dimsout)
new(W,b)
end
end
# overload object definition
(obj::CustomDense)(x) = obj.W * x .+ obj.b
dense = CustomDense(5,2)
dense(rand(5))2-element Vector{Float64}:
0.38609011196942344
1.7445256031830105The dense layer represents the all-to-all connections.
API is Dense(dimsin => dimsout).
Optional keywords are bias=true/false, and activation.
The convolutional layer is specified with Conv((kerneldim1, kerneldim), featuresin=>featuresout)
It accepts keywords stride=(s1,s2), pad=(p1, p2), dilation=(d1,d2), bias, activation.
The layer accepts a 4D tensor: x dimension, y dimension, feature dimension, and data-index.
flatten layers take an input and flatten it to a vector.
Dropout layers freeze a fraction of parameters in learning.
BatchNorm normalises mean/variance.
AlphaDropout layers freeze parameters and normalise mean and variance.
There are extensive pooling layers e.g. MaxPool most common.
Composing a model is simply a chain of layers.
Flux allows this to be intutively done with chain: model(x) = Chain(Dense(10=>3), Dense(3=>5))
A generically complex model can be given by a function f.
Flux can be told this complex function is a model with @functor f.
Data is thought of “naturally” in Flux.
It operates on a single point, or a vector of points.
A convenience function DataLoader is provided.
It zips data pairs and can optionally shuffle with a given batch size.
Loss functions are defined on individual data pairs.
Flux then aggregates them along a batch along the last dimension.
Loss aggregration is by default the average: can be specified with keyword agg.
There are many default loss functions: mse, logitcrossentropy, HuberLoss etc.
We have a model, data, optimisers, and loss functions and can now update parameters.
update! takes an optimiser, gradient values, and updates specified parameters.
update!(opt, Flux.params(w...), grad)
This can be applied through a loop over the data where the gradient is repeatedly computed.
An even easier API to work with is train!.
It accepts a loss function, parameters, a data generator, and optimiser.
train!(loss, Flux.params(w...), data, opt)
A callback function provides a printout under certain conditions.
They are passed as optional keywords to train e.g. train!(...; cb = ()->println("This calls back"))
By default they print every epoch but can be slowed down with cb = throttle(some_func, epoch_interval)
Can be used with Flux.stop() to abort training if a condition is met e.g. accuracy goal, timing limit etc.
A model can be piped into a GPU/CPU device with the gpu and cpu APIs
For a GPU based model the data should be converted to CUDA arrays. Only CUDA is supported.
To save a model we need the BSON package.
A model is saved with @save "dir" model_obj
A model is loaded with @load "dir" model_obj
It is recommended to pipe models to a CPU device before saving.
Within a training loop you can be expressive.
Common to plot loss functions on training and validation sets.
Common to plot a data-visualisation (particularly for generative models)
Can have an indication of training time: elapsed and estimated finish.
using Flux, JLD2
data = JLD2.load("./data/sharks/sharkdata.jld")
training_data, training_labels = [data["train_data"], data["train_labels"]]
model = Chain(
Flux.Conv((3,3), 3=>10, relu),
Flux.MaxPool((2,2)),
Flux.Conv((5,5), 10 => 5, relu),
Flux.MaxPool((2,2)),
Flux.Conv((10,10), 5 => 7, relu),
Flux.flatten,
Dense(112, length(unique(training_labels)), σ))Chain( Conv((3, 3), 3 => 10, relu), # 280 parameters MaxPool((2, 2)), Conv((5, 5), 10 => 5, relu), # 1_255 parameters MaxPool((2, 2)), Conv((10, 10), 5 => 7, relu), # 3_507 parameters Flux.flatten, Dense(112 => 3, σ), # 339 parameters ) # Total: 8 arrays, 5_381 parameters, 22.449 KiB.
@time for e in 1:100 # epochs
d = Flux.DataLoader((training_data, Flux.onehotbatch(training_labels, unique(training_labels))), shuffle=true, batchsize=5)
Flux.train!((x,y) -> Flux.logitcrossentropy(Flux.softmax(model(x)),y), Flux.params(model), d, ADAM())
end
predictions = map(i -> argmax(model(data["test_data"])[:,i]), 1:size(model(data["test_data"]))[2])
labels = ["thresher", "nurse", "basking"]
pred_labels = [labels[predictions[i]] for i in 1:length(predictions)]
@show acc = sum(pred_labels .== data["test_labels"])/length(pred_labels); 30.337100 seconds (39.47 M allocations: 10.089 GiB, 7.34% gc time, 56.53% compilation time)acc = sum(pred_labels .== data["test_labels"]) / length(pred_labels) = 0.8Machine learning is sophisticated methods of optimising an objective/loss function.
Flux allows us to abstract the boiler-plate of machine learning code.
It is fast, flexible, and allows us to define models simply with a chain and layer structure.
Can focus on the conceptual difficulties, rather than the technical challenges.